Repository basics
Creating a Repository
A git repository comes in two flavours. A bare one and one with a
working tree or working directory. Both have a
.git folder where git stores all internal information. This
folder is the core of the repository.
To create a repository we can run git init.
# create a new directory
$ mkdir demo
# change into that directory
$ cd demo
# initialize a new git repository
$ git init
Initialized empty Git repository in /home/martin/src/git_training/demo/demo/.git/Inside a git repository
If we use ls -a to list all files in this directory we
only see a .git folder. On Linux/Unix systems files and
directories starting with a . are hidden,
-a or --all makes sure ls list those
files.
$ ls -a
.
..
.gitTo inspect this folder we can use the tree tool. This
tool may not be installed by default. Depending on your OS/shell there
are different ways to install it.
Everything after a # is manually added and will not be
print by tree.
$> tree .git
.git
├── config # the local config
├── description
├── HEAD # the HEAD, here git keeps track where you are
├── hooks # hooks which can be applied at differnt events
│ ├── applypatch-msg.sample
│ ├── commit-msg.sample
│ ├── fsmonitor-watchman.sample
│ ├── post-update.sample
│ ├── pre-applypatch.sample
│ ├── pre-commit.sample
│ ├── pre-merge-commit.sample
│ ├── prepare-commit-msg.sample
│ ├── pre-push.sample
│ ├── pre-rebase.sample
│ ├── pre-receive.sample
│ ├── push-to-checkout.sample
│ ├── sendemail-validate.sample
│ └── update.sample
├── info
│ └── exclude
├── objects # inside this folder git stores objects
│ ├── info
│ └── pack # here git stores pack files, a optimized, binary format of objects
└── refs
├── heads # here git will store the commit a tip of each branch points to
└── tags # here git will store the commit a tag points to
9 directories, 18 files
## Currenty status and history
`git status` shows the current status of your git repository.
$ git status
On branch oneandonly
No commits yet
nothing to commit (create/copy files and use "git add" to track)As we can see, we are on the branch oneandonly, we do
have no commits and apparently nothing to commit.
git log prints the commit history of the branch we are
on.
$ git log
fatal: your current branch `oneandonly` does not have any commits yetAgain, we do not have a history yet.
The three states
Before we add a file, we need to talk about the three states git uses to manage files.
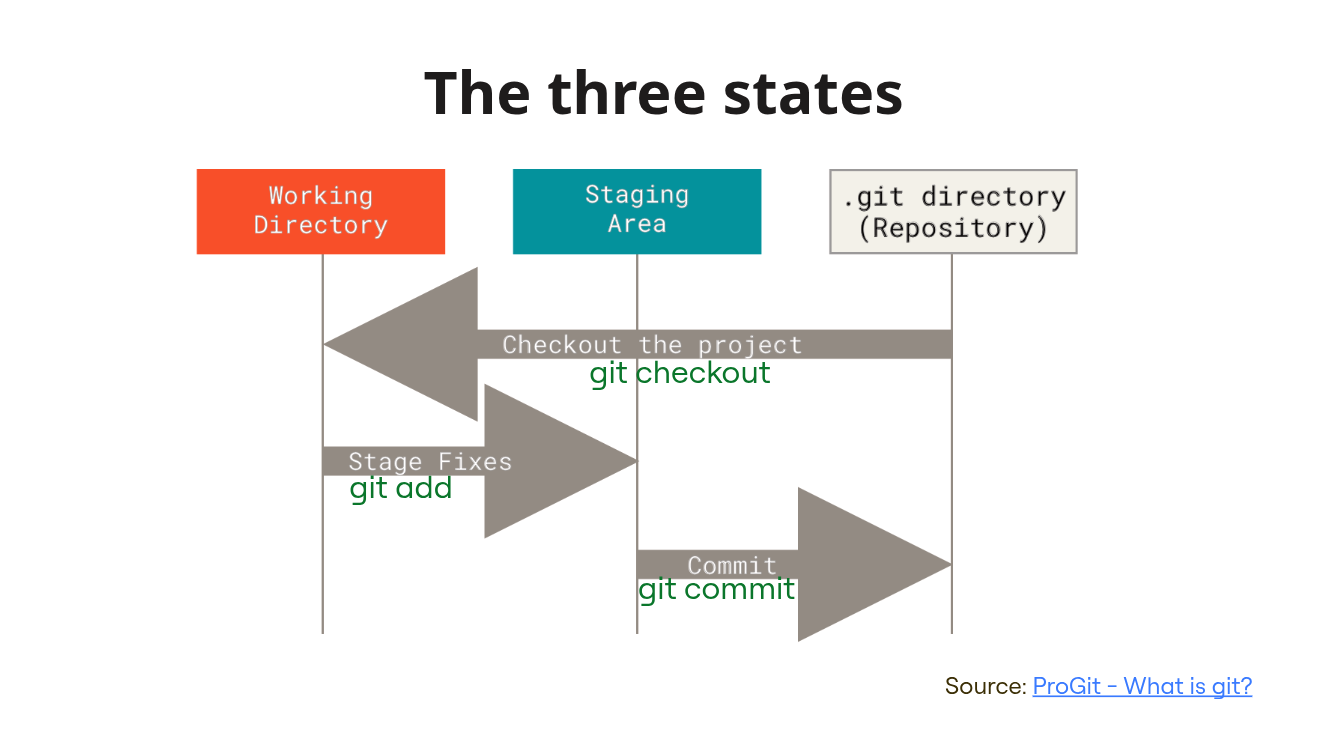
Files in git can be in three states.
Working Directory
Files in here representing you local state of the files in the
repository. If you change some files in here, they will be marked as
changed in the working tree. In here also
untracked files are present. Untracked files are files, git
does not know about and will not take under version control until you
add them.
Staging Area
Files in here are in the staging area. The staging area is kind of a
middle ground. You can add changed files to it, git will basically
create a copy of these files for future use. If you change the same file
in your working directory the staged copy is not affected! You also can
restore your copy in the working directory to the content of the file
changed with git restore. Using
git restore --staged will unstage the file, restoring the
index. The staging area represents the next commit you are
working on. All files in these area will be part of your next commit.
The index file is vital for this area.
.git directory
The .git directory is also called the repository. When a file is
committed to the repository with git commit a snapshot of
this files content is stored.
You can read more about this in the Pro Git book.
Staging a file
Before we can commit a file, the file must be staged.
# create a file called `myfile.txt` with a line `myfile` in it
$ echo myfile > myfile.txt
$ git status
On branch oneandonly
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
myfile.txt
nothing added to commit but untracked files present (use "git add" to track)Git tells the file myfile.txt is untracked and we need
to add it to commit it.
$ git add myfile.txt
$ git status
On branch oneandonly
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: myfile.txtNow myfile.txt is staged. Remember how the staging area works? It keeps a copy of the
file contents. What will happen when the staged file is changed in the
working directory?
# append a line to `myfile.txt`
$ echo `append this line` >> myfile.txt`
$ git status
On branch oneandonly
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: myfile.txt
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: myfile.txt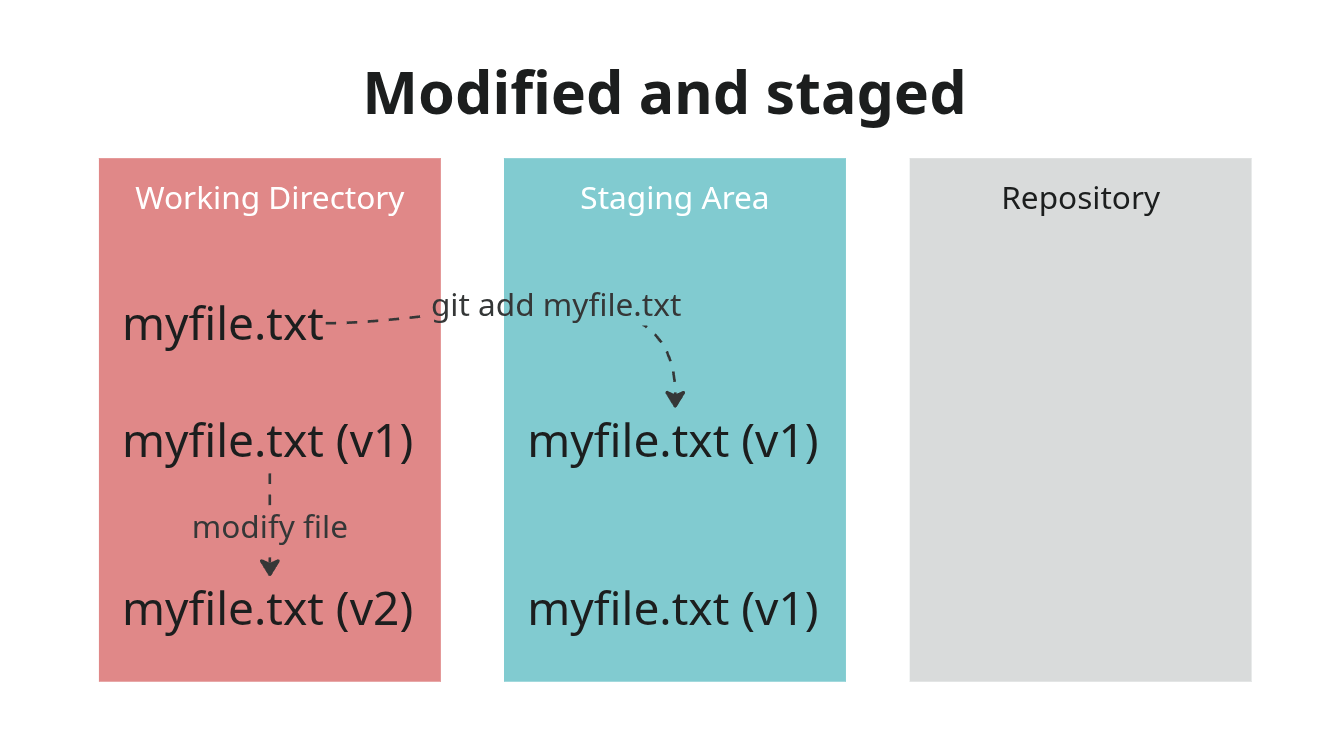
When myfile.txt was staged git stored its contents on
the staging area. This basically stored version 1 on the file. Then the
file was changed in the working directory and now there is a version 2
of the file. But version 2 is only present in the working directory and
not in the staging area. A commit will only include version 1. For now,
we still do not have any commits.
The Staging Area and the index file
When we look into the .git folder again, we notice some
changes. Again, everything after a # is a manually added
comment.
$ tree .git
.git
├── config
├── description
├── HEAD
├── hooks
│ ├── applypatch-msg.sample
│ ├── commit-msg.sample
│ ├── fsmonitor-watchman.sample
│ ├── post-update.sample
│ ├── pre-applypatch.sample
│ ├── pre-commit.sample
│ ├── pre-merge-commit.sample
│ ├── prepare-commit-msg.sample
│ ├── pre-push.sample
│ ├── pre-rebase.sample
│ ├── pre-receive.sample
│ ├── push-to-checkout.sample
│ ├── sendemail-validate.sample
│ └── update.sample
├── index # this new file is the index file
├── info
│ └── exclude
├── objects
│ ├── 20
│ │ └── f11a5545b04a86ca81f7a9967d5207349052d7 # a object was added
│ ├── info
│ └── pack
└── refs
├── heads
└── tags
10 directories, 20 filesTwo new files are present. A index file and a git
object.
The index file
The index file is a binary file where git stores
information about the staging area. If you are interested in a more
through explanation, consider looking at the documentation of the index file format. We
only inspect this file with two handy tools.
filewill show us information about the type of a filestringswill print all available strings of a (binary) file
$ file .git/index
.git/index: Git index, version 2, 1 entries
$ strings .git/index
DIRC
myfile.txtWe now know, the index file has 1 entry and it contains the string
myfile.txt. Taken this together, git seems to store the
filename of the staged file in the index file. But where does it store
the content?
The git object
We will look at git objects in more detail later. For now we only
look at it's content. This can be done with
git cat-file -p objectId.
$ git cat-file -p 20f11a5545b04a86ca81f7a9967d5207349052d7
myfileThis is the content of our staged file!
Taking this together: When we stage a file, git creates a object for its content and adds it to the index file.
Committing a file
Time to introduce a different output for git status. Git
status is rather lengthy and verbose. git status --short is
much more concise.
$ git status --short
AM myfile.txtThe first column (A) show the status of the staged file. The second
column (M) shows the status of the file in the working directory. Here
we see, we added the file to the stage and
modified it in the working dir. Use
man git status to review the short output format if there
are questions.
git commitopens a editor. The editor which is opened is defined in your git
configuration under core.editor.
# Please enter the commit message for your changes. Lines starting
# with `#` will be ignored, and an empty message aborts the commit.
#
# On branch oneandonly
#
# Initial commit
#
# Changes to be committed:
# new file: myfile.txt
#modify the file to look like this
first commit
body
# Please enter the commit message for your changes. Lines starting
# with `#` will be ignored, and an empty message aborts the commit.
#
# On branch main
#
# Initial commit
#
# Changes to be committed:
# new file: test
#then save and quit.
[oneandonly (root-commit) 215b0b5] first commit
1 file changed, 1 insertion(+)
create mode 100644 myfile.txt
$ git log
commit 215b0b5cc01dc4a637e82a42e694efe0a37451c9
Author: maschmi <maschmi@maschmi.net>
Date: Sun Jun 15 11:14:55 2025 +0200
first commit
bodyBut what does the commit contain? git show prints git
objects. In cases of commits it also adds a diff to it. The diff tells
us what has changed with this commit.
$ git show 215b0b5
commit 215b0b5cc01dc4a637e82a42e694efe0a37451c9
Author: maschmi <maschmi@maschmi.net>
Date: Sun Jun 15 11:14:55 2025 +0200
first commit
body
diff --git a/myfile.txt b/myfile.txt
new file mode 100644
index 0000000..20f11a5
--- /dev/null
+++ b/myfile.txt
@@ -0,0 +1 @@
+myfileThe diff
Let's look at the diff for a moment, comments on how to read the line
will be added above it, after a #.
# the difference to be shown is between a/myfile.txt and b/myfile.txt
diff --git a/myfile.txt b/myfile.txt
# it is a new file and has ode 100644
new file mode 100644
# the difference is between index 000000 and 20f11a5 <- this is a git object
index 0000000..20f11a5
# from file: in our ase /dev/null as it was not present before
--- /dev/null
# to-file: in our case b/myfile.txt our commited file
+++ b/myfile.txt
# -from-file-line numbers +to-file-line-numbers
@@ -0,0 +1 @@
# this line was added (a - would suggest a delete)
+myfileThis is a format very similar to the unified diff format
Git Objects
Let's look at the git object present in .git.
# find all files in .git/objects
$ find .git/objects -type f
.git/objects/20/f11a5545b04a86ca81f7a9967d5207349052d7
.git/objects/e5/c3e4f7fb6cb33ad7aa67fe4905899188f0e758
.git/objects/21/5b0b5cc01dc4a637e82a42e694efe0a37451c9We see three objects. The first object already existed. That is the
one which was created when we staged the file. It holds the contents of
myfile.txt.
Using git cat-file -t we can print the type. The script
print_objecttype.sh does this for each git object.
$> ../print_objecttypes.sh
20f11a5545b04a86ca81f7a9967d5207349052d7 blob
e5c3e4f7fb6cb33ad7aa67fe4905899188f0e758 tree
215b0b5cc01dc4a637e82a42e694efe0a37451c9 commitWe see three types of files
- blob
- tree
- commit
The script print_objects.sh does the same but uses
git cat-file -tand git cat-file -p to combine
type and content. The output format is as follows:
---
objectId type
contents
$ ../print_objects.sh
----
20f11a5545b04a86ca81f7a9967d5207349052d7 blob
myfile
----
e5c3e4f7fb6cb33ad7aa67fe4905899188f0e758 tree
100644 blob 20f11a5545b04a86ca81f7a9967d5207349052d7 myfile.txt
----
215b0b5cc01dc4a637e82a42e694efe0a37451c9 commit
tree e5c3e4f7fb6cb33ad7aa67fe4905899188f0e758
author maschmi <maschmi@maschmi.net> 1749978895 +0200
committer maschmi <maschmi@maschmi.net> 1749978895 +0200
first commit
body
----Blob Objects
Blob objects contain only contents. No filenames, no version, no diffs. They represent a snapshot of a file content. Same content, means same objectId.
Tree objects
Tree objects are like a directory listing. They can contain pointers to multiple blobs and multiple other trees (think: subdirectory). Tree objects also contain the mode of a blob or a tree (e.g. 100644).
Commits
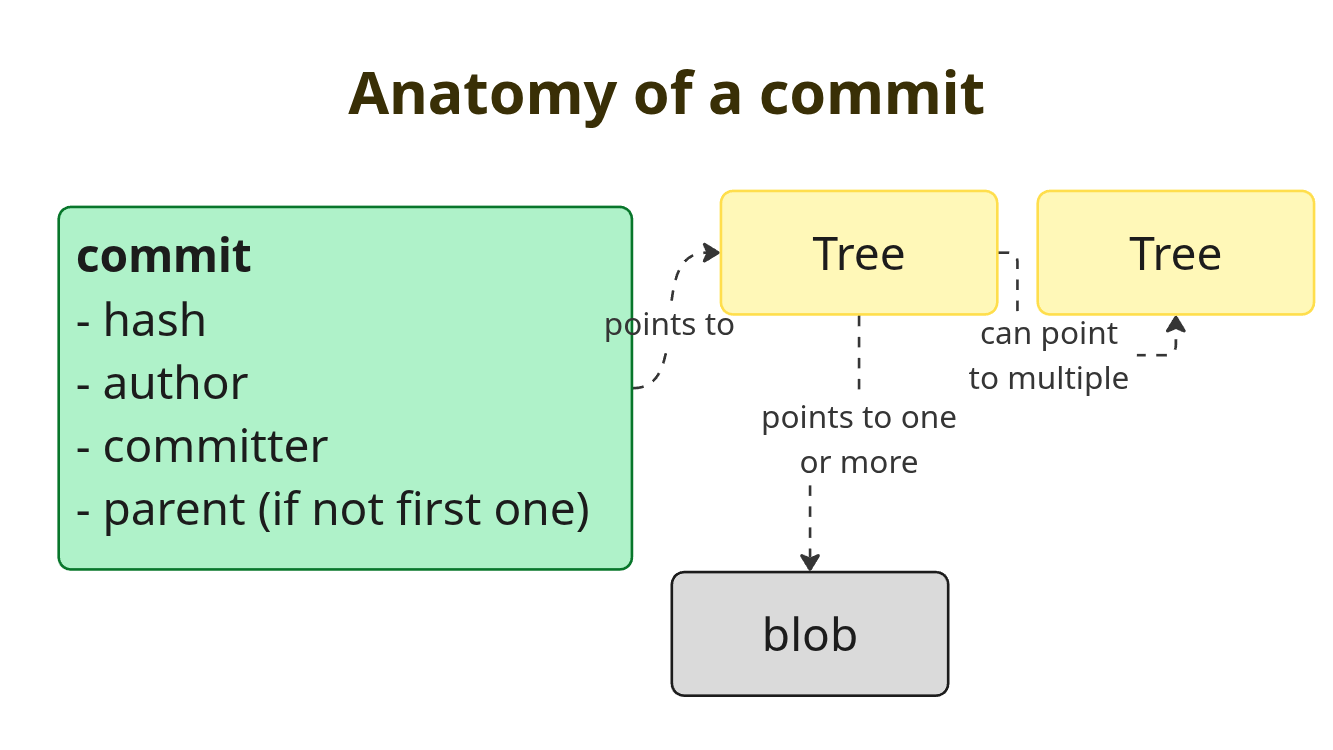
Commit object hold information of a commit. The commit points to a tree, basically the snapshot of the current staging area and all other tracked files. The commit object also contains an author, a committer and usually one parent (as long as it is not the first commit or a merge commit). Also the commit message is store in the commit object.
For a more in depth explanation about git-object, please refer to the Pro Git book.
A second commit
We will now create a directory, copy myfile.txt under a
different name into it, stage all changes and commit them using a short
form of the git commit command. git commit -m
takes a commit message directly after the -m flag.
# create directory
$ mmkdir doc
# copy myfile to doc/README
$ cp myfile.txt doc/README
# stage all files reachable from the current directory
$ git add .
# commit all staged files and set the commit message to "second commit"
$ git commit -m "second commit"
[oneandonly 17e1e8d] second_commit
2 files changed, 3 insertions(+)
create mode 100644 doc/READMENow let's look at the objects again.
$ ../print_objects.sh
----
20f11a5545b04a86ca81f7a9967d5207349052d7 blob
myfile
----
e5c3e4f7fb6cb33ad7aa67fe4905899188f0e758 tree
100644 blob 20f11a5545b04a86ca81f7a9967d5207349052d7 myfile.txt
----
215b0b5cc01dc4a637e82a42e694efe0a37451c9 commit
tree e5c3e4f7fb6cb33ad7aa67fe4905899188f0e758
author maschmi <maschmi@maschmi.net> 1749978895 +0200
committer maschmi <maschmi@maschmi.net> 1749978895 +0200
first_commit
body
----
c71e21c812febfeb4c02c9bebc3944549e89de67 blob
myfile
append this line
----
a248d81b5fc30d76ff09aef520029732074232b8 tree
100644 blob c71e21c812febfeb4c02c9bebc3944549e89de67 README
----
87d4c1bad1f4b9ce25e24066ed99b48baeb8325e tree
040000 tree a248d81b5fc30d76ff09aef520029732074232b8 doc
100644 blob c71e21c812febfeb4c02c9bebc3944549e89de67 myfile.txt
----
17e1e8d94758c94c903b756d72729194a2612d30 commit
tree 87d4c1bad1f4b9ce25e24066ed99b48baeb8325e
parent 215b0b5cc01dc4a637e82a42e694efe0a37451c9
author maschmi <maschmi@maschmi.net> 1749978896 +0200
committer maschmi <maschmi@maschmi.net> 1749978896 +0200
second commit
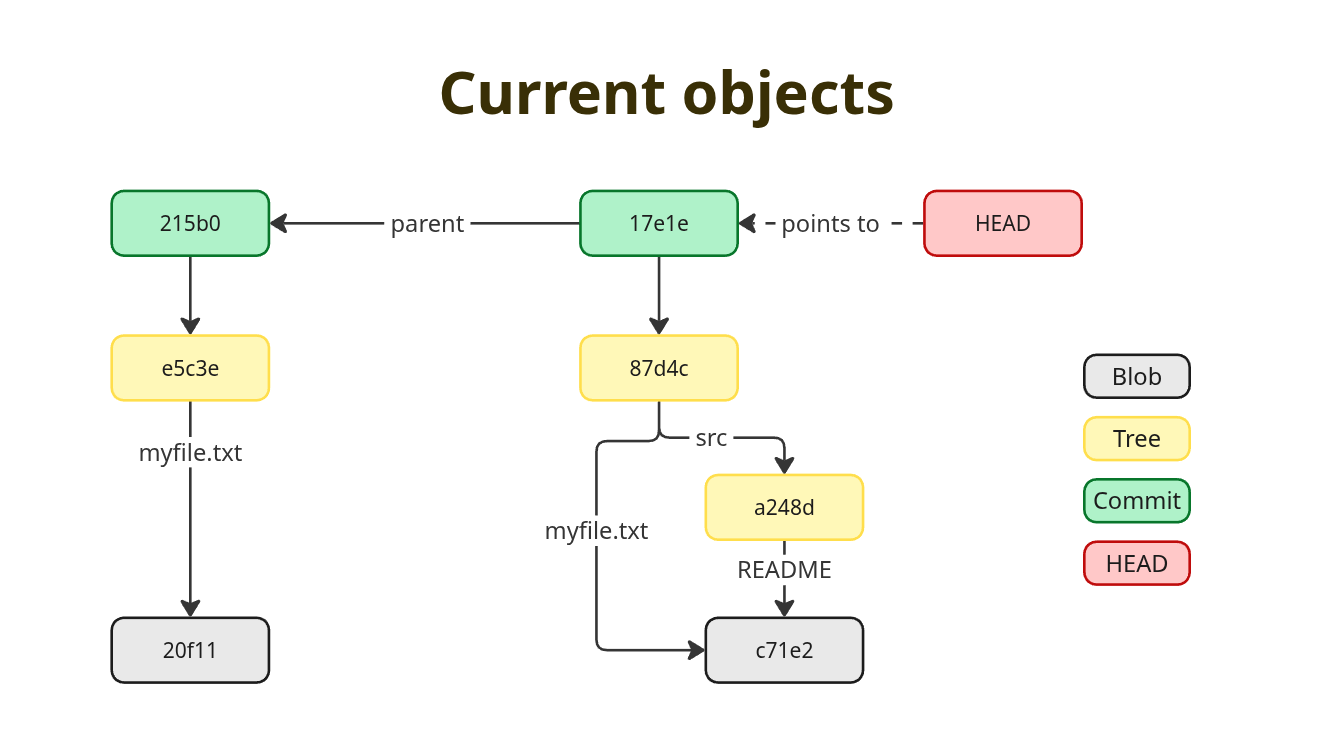
----We can see, git still holds all the old objects and still only adds
to them. We have a new commit 17e1e which has a parent
215b0 (out first commit). It points to a tree
87d4c which in turn points to a blob c71e2
(myfile.txt) and another tree a248d (doc). The
a248d (doc) tree point to a blob c71e2
(README). Wait, README and myfile.txt share
the same blob? Well, same content, same checksum, same blob. The
filename is stored inside the tree. Git does not duplicate already
existing files or duplicates identical content when writing a new
commit! Our old commit 215b0 still points to the tree
e5c3e which points to the blob 20f11 which
contains the content of our first version of
myfile.txt.
Graphically it would look like this:
The HEAD

One thing left to explain for now. The HEAD. The HEAD stores a
pointer to the current revision we are working on. If the current
revision is the tip of a branch, the HEAD points to
.git/refs/main which in turn points to the commit at the
tip of the branch. The HEAD is in attached mode. The HEAD can also point
directly to a revision (commit). If this is the case the HEAD is in
detached HEAD mode.
$ git checkout e25c7
You are in `detached HEAD` state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by switching back to a branch.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -c with the switch command. Example:
git switch -c <new-branch-name>
Or undo this operation with:
git switch -
Turn off this advice by setting config variable advice.detachedHead to false
HEAD is now at e25c7 first commit
# print contents of file to stdout
$ cat .git/HEAD
215b0b5cc01dc4a637e82a42e694efe0a37451c9Use git checkout oneandonly to attach the HEAD again and
checkout the most current revision.